CL4SREC은 전통적인 ‘next item prediction’ 태스크의 장점을 이용할 뿐만 아니라 contrastive learning의 프레임워크를 사용하여 아이템 시퀀스로부터 self-supervision signal을 추출한다. 그렇기에 더욱 의미 있는 유저 패턴을 추출할 수 있고 유저 표현을 더욱 효과적으로 인코딩할 수 있다.
논문 : Contrastive Learning for Sequential Recommendation
Self-supervised Learning(SSL, 자기지도학습)
self-supervised learning은 라벨없는 데이터에서 representation을 학습하는데에 우월하다고 한다. 기본 아이디어는 pretext task로 training signal을 구축하는 것이다.
CL4SREC
Notations & 문제 정의
유저를 \(u\), 아이템을 \(v\)라고 하자. 유저 \(u\)의 인터랙션 시퀀스 \(s_u\)는 \(s_u=\left[v_1^{(u)}, v_2^{(u)}, \cdots, v_{|s_u|}^{(u)}\right]\)처럼 쓸 수 있다. 여기서 \(|s_u|\)는 시퀀스 길이가 된다.
시퀀셜 추천을 정의하자. 유저 \(u\)가 \(|s_u|+1\) 시간에 가장 상호작용할 가능성이 높은 아이템을 예측한다. 다른 보조적인 문맥 정보는 사용하지 않고, 오직 유저의 상호작용 시퀀스만 주어진다. 다음과 같이 수식화된다.
\[v_u^* = \arg\max_{v_i \in \mathcal{V}} P\left( v_{|s_u|+1}^{(u)} = v_i | s_u \right)\]Contrastive Learning Framework
프레임워크는 크게 세 가지로 구성된다.
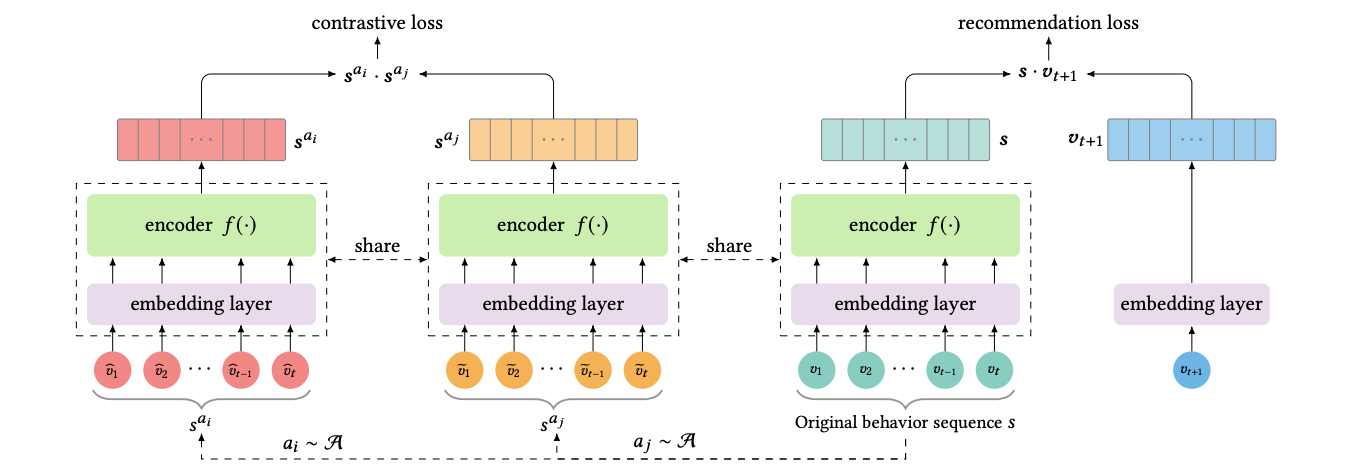
1. 증강 모듈(Data Augmentation Module)
\(\mathcal{A}\)를 augmentation method들의 집합이라고 하자. 즉 \(\mathcal{A}\)에는 뒤에 나올 crop, mask, reorder가 들어있다. 증강 모듈은 하나의 데이터에 대해 2개의 augmentation을 만든다. 만약 두 augmentation이 같은 샘플로부터 나온 것이라면 이 둘은 positive pair라고 정의한다. 각각 다른 샘플로부터 변형된 것이라면 negative pair라고 정의한다. Augmentation 방법은 \(\mathcal{A}\)로부터 무작위로 2개를 뽑아 \(a_i\)와 \(a_j\)라고 부르기로 하고(예를 들면 \(a_i\) : Crop, \(a_j\) : Mask), 이를 \(s_u\)라는 시퀀스에 적용한다. 결과는 각각 \(s_u^{a_i}\)와 \(s_u^{a_j}\)라고 나타낸다.
2. 유저 인코더(User Representation Encoder)
인코더로 트랜스포머를 사용한다. 증강된 시퀀스로부터 유저 representation을 추출한다.
3. 대조 손실 함수(Contrastive Loss Function)
손실함수는 두 representation이 같은 유저 시퀀스로부터 추출된 것인지 구별한다. 손실함수는 다음을 각각 최소화, 최대화한다.
- 최소화 : 하나의 유저시퀀스로부터 변형된 두 시퀀스간 차이
- 최대화 : 각각 다른 유저 시퀀스로부터 변형된 두 시퀀스간 차이
\(\text{sim}(u, v)=u^Tv\), 즉 내적이다. 손실을 작게 한다 = -를 뗀 log를 크게 한다 = \(s_u^{a_i}\)와 \(s_u^{a_j}\)를 유사하게 한다 + \(s_u^{a_i}\)와 \(S^-\)에 속한 것들과는 멀어지게 한다가 되겠다.
Data Augmentation Operators

1. Crop
시퀀스 내부의 연속된 일부만 떼어낸다. 예를 들어 \([v_1, v_2, v_3, v_4, v_5, v_6, v_7]\)이라는 7개의 아이템으로 구성된 시퀀스가 있고, 전체 길이 7의 0.6만큼만 crop한다고 하고(내림하여 4개), 2번 아이템부터 crop한다고 했을때 augmentation 결과는 \([v_2, v_3, v_4, v_5]\)가 된다.
2. Mask
일부 아이템을 \([mask]\)라는 스페셜 아이템으로 변환한다. 만약 시퀀스 길이의 0.3만큼만 마스킹하고싶다면 7 X 0.3 = 2.1을 내림한 2개를 랜덤으로 마스킹한다.
3. Reorder
시퀀스 내부의 연속된 시퀀스를 무작위 재배치한다. 예를들어 3번 아이템부터 0.6만큼의 아이템, 즉 4개를 재배치한다면 \([v_1, v_2, v_5, v_3, v_6, v_4, v_7]\)처럼 된다.
User Representation Model
인코더 모델로는 SASRec을 사용한다(SASRec 논문리뷰 참고). 유저 representation으로는 마지막 아이템까지 어텐션을 적용한 representation, 즉 \(t=|s_u|\)(마지막)째 아이템의 representation을 사용한다.
Multi-task Training
multi-task 전략을 사용한다고 하는데, 특별한게 아니다. \(\mathcal{L}_{\text{cl}}\)뿐만 아니라 SASRec 자체의 next item prediction 손실까지 더하겠다는 뜻이다. 이를 \(\mathcal{L}_{\text{main}}\)이라고 할 때, total loss는 다음과 같다. \(\mathcal{L}_{\text{total}} = \mathcal{L}_{\text{main}} + \lambda \mathcal{L}_{\text{cl}}\)
\(\mathcal{L}_{\text{main}}\)은 다음과 같이 정의된다.
\[\mathcal{L}_{\text{main}}(s_{u, t}) = \frac{\exp(s_{u,t}^T v_{t+1}^+)}{\exp(s_{u, t}^T v_{t+1}^+) + \sum_{v_{t+1}^- \in \mathcal{V}^-} \exp(s_{u,t}^T v_{t+1}^-)}\]\(s_{u, t}\)는 계산된 유저 representation을 의미하고, \(v_{t+1}^+\)는 \(t+1\)에서의 아이템, \(v_{t+1}^-\)는 무작위 샘플링된 네거티브 아이템을 의미한다.
Experiments
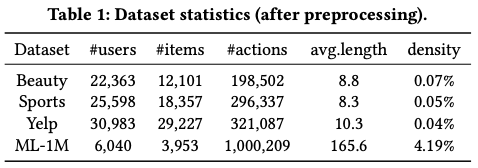
사용한 데이터셋은 다음과 같다.
Crop, mask, reorder에서 사용하는 비율은 다음과 같다.
- crop : \(\eta\)(eta)
- mask : \(\gamma\)(gamma)
- reorder : \(\beta\)(beta)