ABSTRACT
과거에 CoT 프롬프팅과 같은 Reasoning(추론), 액션 계획을 생성하는 것 등의 Acting(행동)은 따로 연구되어 왔다. 이 논문에서는 추론 흔적(reasoning traces)과 행동(action)이 합쳐져 더욱 큰 시너지를 낸다는 걸 보여줍니다. 이 방식에 ReAct(Reasoning + Acting)라는 이름을 붙였습니다.
ReAct는 할루시네이션을 해결할 수 있다고 하네요. 위키피디아 API를 이용해 검색하고, 인간이 문제를 해결하는 단계들을 스스로 생성한다고 합니다. 즉, 더 interpretable 해진다고 하네요.
1 INTRODUCTION
인간이 문제를 풀 때 하는 ‘말’ 또는 ‘머릿속으로 생각하기’들을 하는 것은 논리적으로 풀 수 있게 하는 중요한 과정입니다.
요리를 한다고 해봅시다. 인간은 언어를 이용해 요리 과정을 정리하고 추론하죠!! “재료 다 잘랐으니, 물을 끓여야 해.” 처럼요. 예상치 못한 문제가 발생했을 때도요. “소금이 없네! 간장이랑 후추로 대신해야지.” 처럼요. 외부 지식이 필요할 때도 있습니다. “도우 어떻게 만들지? 검색해봐야겠다” 처럼요.
또한 행동하죠! 요리책을 읽고, 냉장고를 열고, 재료를 확인하죠. 왜죠? 위에서 한 추론들을 행동을 통해서 결과를 확인해야 하기 때문입니다. “내가 만들 수 있는 음식들은 무엇이 있지?”같은 물음이 생기면 행동해서 알아봐야 하잖아요.
이처럼 인간은 추론과 행동의 긴밀한 시너지를 발생시킴으로써 처음 보는 문제를 해결하기도 하고, 정보가 부족한 상황에서도 괜찮은 결정을 할 수 있습니다.
CoT만 쓰면 문제는? 학습된 지식만 사용하기 때문에 할루시네이션이 발생할 수 있습니다.
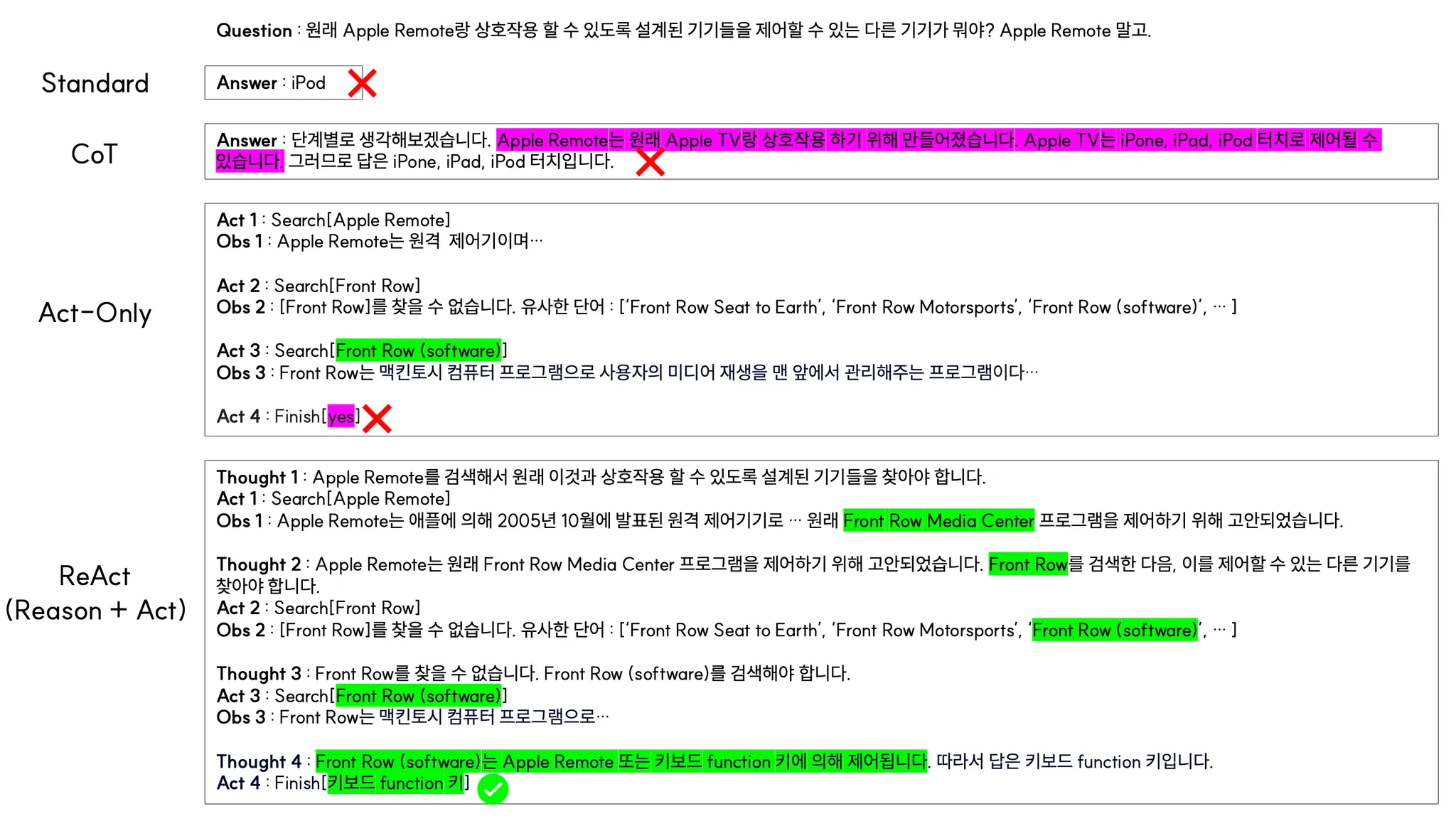
 아이폰, 아이패드, 아이팟은 Apple TV를 조작하지 못하는데… 얘 왜이러니.. 잘못 알고있으니 CoT를 써도 틀림
아이폰, 아이패드, 아이팟은 Apple TV를 조작하지 못하는데… 얘 왜이러니.. 잘못 알고있으니 CoT를 써도 틀림
ReAct는 추론 흔적(reasoning traces)과 행동(actions)을 번갈아가며 생성하도록 프롬프팅합니다. 정확히는 교차적으로(interleaved manner)라고 써있는데요. 뒤에서 예시를 보면 더 정확한 이해가 가능할 것 같습니다. 이를 통해 Reason to act, 즉, 행동하기 위한 추론이 가능하다고 합니다. 또한 Act to reason, 즉, 추론을 위해서 위키피디아 검색같은 것을 할 수 있다고 합니다.
ReAct 방법론 설명 전 예시 먼저 해석


Hotspot QA라는 데이터셋 예시 안에서 Apple Remote라는 리모컨과 Front Row라는 화면이 나옵니다. 그리고 물어봅니다. “원래 Apple Remote와 통신할 수 있도록 만든 프로그램을 제어할 수 있는 Apple Remote 이외의 다른 장치가 뭐야?”

다른 예시로 AlfWorld라는 데이터셋에서 다음과 같이 물어봅니다. “넌 방의 가운데 위치해 있어. 주변을 빠르게 둘러보면 수납장 6, 수납장 1, 커피머신 1, 조리대 3, 버너 1, 토스터기 1이 보여. 너의 임무는: 후추통을 서랍위에 올려놔.”
2 REACT: SYNERGIZING REASONING + ACTING
시간 $t$에서 에이전트는 $o_t \in \mathcal{O}$라는 관측(observation)을 받고, 행동(action)인 $a_t \in \mathcal{A}$을 받는다. 이는 $\pi(a_t \vert c_t)$라는 정책을 따르는데, 이 때 문맥(context)는
\[c_t = (o_1, a_1, \cdots, o_{t-1}, a_{t-1}, o_t)\]와 같이 정의된다. 관측과 행동의 시퀀스라고 생각하면 될 것 같다.
어떤 컨텍스트가 쌓였다고 하자. 그 다음엔 어떤 행동을 해야할까? 즉 $c_t \mapsto a_t$, 문맥 $c_t$가 $a_t$로 변환되는 관계 말이다. 매핑이 명확하지 않고(implicit), 많은 계산량을 필요로 할 때는 이 정책을 학습시키는 것이 어려워진다.

Apple Remote가 뭔지 검색하고, Front Row에 대해 검색하고, Front Row(software)에 대해 검색해 보았다. 근데 행동 4는 ‘yes’라는 허무한 대답을 반환하며 끝나버렸다. 행동 1~3과 관측 1~3에 걸친 긴 히스토리(논문에서는 trajectory라는 표현 씀)에서 복잡한 추론을 해야했기 때문이다.

유사하게 할루시네이션이 일어나는 예시를 보자. “후추통을 서랍위에 올려놓아”라고 명령했었다. LLM은 우선 서랍 1을 열어(행동 2) 수세미 2(dishsponge 2)와 숟가락 1이 있는걸 확인했고(관측 2), 싱크대 1(sinkbasin 1) 위에 수세미 3, 주걱 1(spatula 1), 숟가락 2가 있는 것을 보았다(관측 3). 그런데, 그 다음 행동 4에서는 뜬금없이 싱크대 1에 있지도 않은 후추통 1을 집으려고 한다. 문맥(context)을 이해하지 못하고 할루시네이션 행동을 한다.
특징 및 장점 나열!
-
은 건너뛰고..
ReAct는 간단하다! 에이전트의 행동 공간을 증강한다. 이 때 새롭게 추가되는 액션은 언어 공간에 있다. 이들을 생각(thought) 또는 추론 흔적(reasoning traces)라고 부를 것이다. 이들은 외부 환경에 영향을 미치지 않아서 관측 피드백도 없다. 대신, 새로운 행동은 현재 컨텍스트들을 추론함으로써 유용한 정보를 구성하는 것을 목표로 하고, 문맥을 업데이트하여 미래 추론, 행동을 보조한다.
사진 1에서 볼 수 있는 것처럼, 다양한 유용한 생각들을 볼 수 있는데, 예를 들면 목표를 잘게 쪼개서 행동 계획을 생성하거나, 상식을 주입한다거나, 관측으로부터 중요한 부분만 추출한다거나, 과정을 ㅊ적하고 행동 계획을 변경한다거나, 예상치 못한 상황을 처리하고 행동 계획을 수정한다거나. 그런 것들이다.
그러나, 언어 공간 $\mathcal{L}$은 제한이 없어서, 이 증강된 행동 공간속에서 학습하는건 어려운 일이고 매우 파워풀한 언어적 사전지식을 필요로 한다. 본 논문에서는 PaLM-540B에 초점을 맞췄다. Few-shot in-context 예시를 프롬프팅하여 도메인-특화 행동과 free-form(형태가 정해지지 않은) 언어적 생각을 둘 다 생성한다. 각각의 in-context 예시는 행동, 생각, 환경 관측의 사람 흔적이며 태스크 인스턴스(?)를 풀기 위한 것이다. 추론이 가장 중요한 task(Figure 1(1))의 경우, 생각(thoughts)와 행동(actions)을 번갈아 생성한다. 이를 통해 ‘생각-행동-관찰’이 여러개 묶여서 trajectory를 구성하게 됩니다. 이와는 대조적으로, 잠재적으로 대량의 행동(actions)와 연관된 의사 결정을 하는 task의 경우(Figure 1(2)), 생각(thoughts)은 trajectory 상에서 가장 중요한 위치에 소수만 등장해도 된다. 그래서 우리는 언어모델이 생각과 행동의 발생을 비동기적으로 스스로 결정하도록 한다.
ReAct에서는 의사 결정 능력과 추론 능력이 둘 다 LLM으로부터 나오기 때문에, 몇가지 특이한 점이 있다.
A. 직관적이며 설계가 쉽다 : 사람이 자신의 행동에 대해 써내려가는 것처럼, 프롬프팅이 직관적입니다.
B. 범용적이고 유연하다 : 유연한 생각(thoughts) 공간과 생각-행동 발생 형식 때문에, ReAct는 다양한 작업에 각각의 행동 공간과 추론이 사용될 수 있다. Question-Answering에만 제한된게 아니고 사실 확인, 글자 게임, 웹 네이게이션 같은데에서도 말이다.
C. 우수한 성능과 견고성
D. 인간이 이해할 수 있으며 통제할 수 있는 모델
3 KNOWLEDGE-INTENSIVE REASONING TASKS
‘Knowledge-intensive’는 ‘지식 집약적인’이라는 뜻으로 통용되는 것 같습니다. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks에 따르면, Knowledge Intensive Tasks란 ‘사람조차도 외부 지식(ex. 위키피디아 검색) 없이 해결하기 어려운 문제’라고 하네요. 본 섹션에서는 복잡한 정보가 필요한(=지식 집약적인) 추론 작업, 즉 여러 단계를 거쳐야 하는 Question-Answering과 팩트 체크와 같은 작업을 다뤄본다고 합니다.
ReAct를 사용하면 위 그림과 같이 위키피디아 API를 사용하여 추론을 도와줄 수 있는 검색을 할 수 있고, 그 다음에 필요한 정보가 무엇인지 알아내기 위해 다시 추론을 사용한다고 합니다.
데이터셋은 다음 두 가지를 사용했다고 합니다.
- Hotpotqa: A dataset for diverse, explainable multi-hop question answering(2018)
- FEVER: a large-scale dataset for fact extraction and VERification(2018)
HotpotQA는 Question-Answering 데이터셋이며 113,000개의 위키피디아 기반 question-answer 쌍으로 되어있다고 합니다. FEVER에는 사실 검증을 위한 벤치마크 데이터셋으로 185,445개의 주장(claim)이 있으며, 각 주장은 주장은 SUPPORTS(지지됨, 주장을 뒷받침하는 위키백과 문서가 존재하는 경우), REFUTES(반박됨, 주장이 위키백과 문서에 의해 반박되는 경우), NOT ENOUGH INFO(정보 부족, 주장을 검증할 수 있는 충분한 정보가 위키백과 문서에 존재하지 않는 경우) 중 하나로 분류됩니다.
HotpotQA부터 살펴봅시다.

위 이미지는 HotpotQA 데이터셋의 샘플인데요, 단락 A와 B가 있습니다. 파란색 이탤릭체는 supporting facts라고 합니다. 내용은 대략 이렇습니다. (Hotpot이라는 이름은 저자들이 중국식 전골인 hot pot 식당에서 아이디어를 떠올려서 그렇다고 합니다)
단락 A, Return to Olympus:
[1] ‘Return to Olympus’는 록밴드 Malfunkshun의 유일한 앨범이다. [2] 이 앨범은 밴드가 해체된 후, 그리고 리드 싱어였던 Andrew Wood(나중에 Mother Love Bone의 멤버)가 1990년에 약물 과다복용으로 사망한 후 발매되었다. [3] Pearl Jam의 Stone Gossard가 곡들을 모아 자신의 레이블인 Loosegroove Records에서 앨범을 발매했다.
단락 B, Mother Love Bone:
[4] Mother Love Bone은 1987년에 미국 시애틀에서 결성된 록 밴드였다. [5] 이 밴드는 1987년부터 1990년까지 활동했다. [6] 프런트맨(밴드나 그룹에서 공연을 이끌어가며 그룹의 이미지를 좌우하는 사람) Andrew Wood의 개성과 작곡 실력은 1980년대 후반과 1990년대 초반 시애틀 음악 scene에서 이 밴드를 정상으로 끌어올리는 데 큰 역할을 했다. [7] Wood는 밴드의 데뷔 앨범인 Apple이 예정된 출시를 불과 며칠 앞두고 사망했으며, 이는 밴드의 성공 가능성을 끝내는 계기가 되었다. [8] 앨범은 결국 몇 달 후에 발매되었다.
Q: Apple이 출시되기 직전에 사망한 Mother Love Bone의 멤버가 이전에 속했던 밴드는 무엇인가?
A: Malfunkshun
이 질문에 대답하기 위해선 꽤 여러 단계의 Reasoning을 거쳐야 합니다. Multi-hop 문제라고도 부릅니다. [7]을 보면 Apple이라는 앨범은 Mother Love Bone라는 밴드의 데뷔 앨범이었습니다. 근데 Wood라는 사람이 Apple 출시 앞두고 사망합니다. [4],[6]에서 Wood는 Mother Love Bone 밴드의 프런트맨이었습니다. [1]과 [2]를 보면 이 사람은 ‘Malfunkshun’이란 밴드의 리드 싱어였습니다. 그러므로 대답은 ‘Malfunkshun’가 됩니다.
다시 ReAct로 돌아와봅니다. 다음은 Action Space에 대한 설명입니다.
액션은 크게 세 가지입니다.
- search[entity] : entity로 검색한 문서가 존재하면 그 문서의 첫 5문장을 반환합니다. 없으면 Wikipedia 검색엔진에 의한 유사한 entity 상위 5개를 반환합니다.
- lookup[string] : 브라우저의 Ctrl+F 기능으로 해당 string을 찾아, 이 string을 포함하고 있는 페이지의 첫 번째 문장을 반환한다.
- finish[answer] : 끝낸다.